You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
WhatsApp, Facebook and Instagram are down
- Thread starter Zee Ley
- Start date
Jasophoria
Jedi
Now whats app is working again to, and guess what it does first when i click it?
Making back up of my conversations while I have automatic updates and backups turned off, and does not ask for permission, just makes a back up.
Making back up of my conversations while I have automatic updates and backups turned off, and does not ask for permission, just makes a back up.
Jasophoria
Jedi
ok facebook is working again.
Instagram is still the same.
Instagram is still the same.
Her's something additional to consider. Apparently today or tomorrow there should be a hearing in US senate regarding Facebook.

 www.foxbusiness.com
www.foxbusiness.com
 www.foxbusiness.com
www.foxbusiness.com
This is what is being shared on RT Telegram channel:
Facebook whistleblower accuses company of 'tearing our societies apart'
Facebook whistleblower Frances Haugen accused the company of 'tearing our societies apart'
Facebook whistleblower to testify at U.S. Senate hearing next week, lawmakers say
Two U.S. senators said on Tuesday a Facebook Inc. whistleblower will testify at a Senate hearing next week about what one of them called the social media company's "toxic effects" on young users.
This is what is being shared on RT Telegram channel:
Anton Rosenberg, Durov brothers' former partner in VKontakte and Telegram, told RT about possible reasons for the mass social networking failure.
"There are several possibilities, plus there are unofficial rumors that they were there updating the configuration of routers, dropped everything and cut off access to themselves, and almost to the point where the electronic access system in the data centers does not work to physically get to the equipment."
Last edited:
Pluchi
Jedi
Hi, y'all! We heard a national broadcast message on the radio this morning stating "an emergency alert to the following states... (Southern USA states) until 12 pm", it didn't state a reason for it, only that the emergency would be until 12 pm. It was only 5 min before that I had noticed that Whatsapp was not working so I turned on the radio in my car and heard the message. I was panicking, I thought D-day was here. So, I called my family in Venezuela and asked them to get food. You never know, we have had similar experiences there and having food for two weeks at least was necessary. If something happens in the USA, I believe that there would be repercussions in other places.
Last edited:
Avala
The Living Force
"About five minutes before Facebook's DNS stopped working we saw a large number of BGP changes (mostly route withdrawals) for Facebook's ASN."
The technical inclined person who would like to know how this could happen might want to read this:
Understanding How Facebook Disappeared from the Internet
Source:
Now I'm sure they did it themselves, on purpose. No one gives that much elaborate blahblahs explanation just like that . . .
Maria Butina just wrote the following on her Telegram channel (translated from Russian):
So it seems that at least in Russia the thought is that it was all Facebook's own doing, or it was a combined effort to create a need for even greater control.
The strange coincidence of the public disclosure by former Facebook employee Frances Haugen of the company's conscious contribution to the political and social polarization of society and the large-scale failure of FB and other corporate applications somehow does not look like a coincidence. The phenomenon of so-called whistle-blowers (a person revealing non-public or even secret data of some entity, public (Snowden) or private (now: Haugen) is not uncommon for the United States, but not everyone gets a platform on the central American TV channels. I have personally met a lot of such truth tellers at various political gatherings in America, but their names won't tell you anything: nobody ever found out about these revelations, at most a couple of half-mad bloggers published the materials. And then there is 60 Minutes, considered to be the most popular political TV show in the world. And right after Haugen's revelation, the company's messengers and apps go down, leaking users' personal data online.
A coincidence?
Three scenarios are possible:
1. Both events are really coincidences, which is unlikely.
2. Facebook management is distracting attention from the former employee's revelations with a bigger problem.
3. Haugen's revelations plus the massive disruption are more than enough reasons for the American government to take control of a dangerous bigtech "at the request of of the public." It is clear that they are already more than connected, but maybe someone in the company got a little cocky and thought they were holding "God by the beard", so it is time to remind them, so that they do not have to, or better yet, to break the monopolist into a bunch of managed companies with the "right" and obedient people in the management. Divide and conquer, as they say, the more so because the public would definitely help with that, because fear is the best motivator. This is the most likely scenario.
I'm not making a conspiracy here, I just know the history: America has done this innumerable times, both in the foreign policy arena and at home. These guys are pretty clumsy with their methods: templates and manuals are their specialty, because that is the main principle of a capitalist: if something sells, don't change it, as long as the public is eating it up and the money is flowing into their pockets.
Today Haugen speaks at a congressional hearing, and then, I guarantee you, the American public will call on Captain America - the government - to help fight the evil corporations of bigtech.
- Wait," the bigtech will say, "but we helped you in the election and in punishing the 'domestic terrorists' and 'evil Russian hackers' you appointed to fight politically?! How so?! You promised a safe haven to ensure profits.
- Well, my dears," the American diplomat will smile with a malicious grin, "to promise does not mean to marry. Don't tell me you still believe in democracy and freedom. You are naive just like little kids. Get back in the stall.
So it seems that at least in Russia the thought is that it was all Facebook's own doing, or it was a combined effort to create a need for even greater control.
Last edited:
Ocean
The Living Force
Understanding How Facebook Disappeared from the Internet
“Facebook can't be down, can it?”, we thought, for a second.
Today at 1651 UTC, we opened an internal incident entitled "Facebook DNS lookup returning SERVFAIL" because we were worried that something was wrong with our DNS resolver 1.1.1.1. But as we were about to post on our public status page we realized something else more serious was going on.
Social media quickly burst into flames, reporting what our engineers rapidly confirmed too. Facebook and its affiliated services WhatsApp and Instagram were, in fact, all down. Their DNS names stopped resolving, and their infrastructure IPs were unreachable. It was as if someone had "pulled the cables" from their data centers all at once and disconnected them from the Internet.
How's that even possible?
Meet BGP
BGP stands for Border Gateway Protocol. It's a mechanism to exchange routing information between autonomous systems (AS) on the Internet. The big routers that make the Internet work have huge, constantly updated lists of the possible routes that can be used to deliver every network packet to their final destinations. Without BGP, the Internet routers wouldn't know what to do, and the Internet wouldn't work.
The Internet is literally a network of networks, and it’s bound together by BGP. BGP allows one network (say Facebook) to advertise its presence to other networks that form the Internet. As we write Facebook is not advertising its presence, ISPs and other networks can’t find Facebook’s network and so it is unavailable.
The individual networks each have an ASN: an Autonomous System Number. An Autonomous System (AS) is an individual network with a unified internal routing policy. An AS can originate prefixes (say that they control a group of IP addresses), as well as transit prefixes (say they know how to reach specific groups of IP addresses).
Cloudflare's ASN is AS13335. Every ASN needs to announce its prefix routes to the Internet using BGP; otherwise, no one will know how to connect and where to find us.
Our learning center has a good overview of what BGP and ASNs are and how they work.
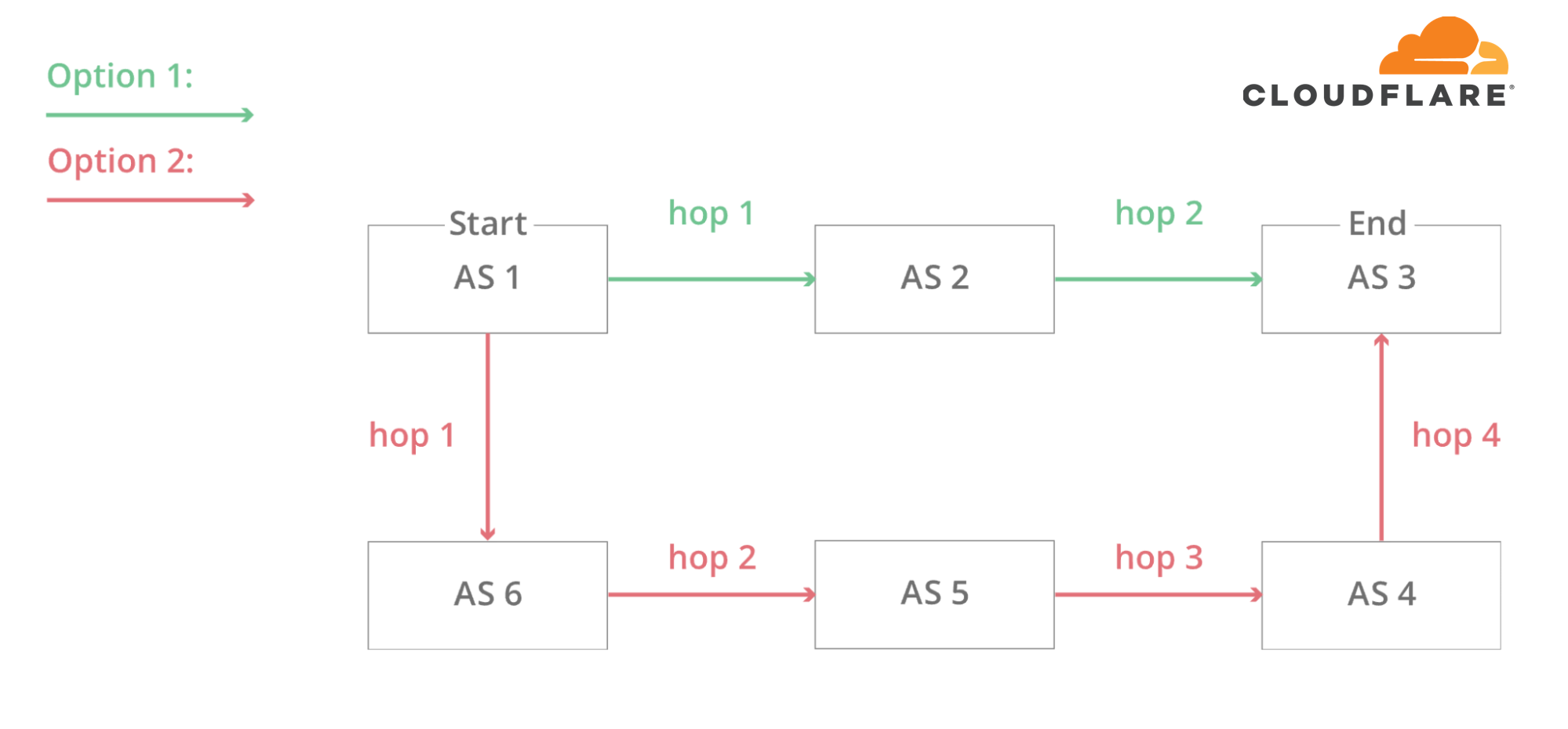
In this simplified diagram, you can see six autonomous systems on the Internet and two possible routes that one packet can use to go from Start to End. AS1 → AS2 → AS3 being the fastest, and AS1 → AS6 → AS5 → AS4 → AS3 being the slowest, but that can be used if the first fails.
At 1658 UTC we noticed that Facebook had stopped announcing the routes to their DNS prefixes. That meant that, at least, Facebook’s DNS servers were unavailable. Because of this Cloudflare’s 1.1.1.1 DNS resolver could no longer respond to queries asking for the IP address of facebook.com or instagram.com.
route-views>show ip bgp 185.89.218.0/23
% Network not in table
route-views>
route-views>show ip bgp 129.134.30.0/23
% Network not in table
route-views>
Meanwhile, other Facebook IP addresses remained routed but weren’t particularly useful since without DNS Facebook and related services were effectively unavailable:
route-views>show ip bgp 129.134.30.0
BGP routing table entry for 129.134.0.0/17, version 1025798334
Paths: (24 available, best #14, table default)
Not advertised to any peer
Refresh Epoch 2
3303 6453 32934
217.192.89.50 from 217.192.89.50 (138.187.128.158)
Origin IGP, localpref 100, valid, external
Community: 3303:1004 3303:1006 3303:3075 6453:3000 6453:3400 6453:3402
path 7FE1408ED9C8 RPKI State not found
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
route-views>
We keep track of all the BGP updates and announcements we see in our global network. At our scale, the data we collect gives us a view of how the Internet is connected and where the traffic is meant to flow from and to everywhere on the planet.
A BGP UPDATE message informs a router of any changes you’ve made to a prefix advertisement or entirely withdraws the prefix. We can clearly see this in the number of updates we received from Facebook when checking our time-series BGP database. Normally this chart is fairly quiet: Facebook doesn’t make a lot of changes to its network minute to minute.
But at around 15:40 UTC we saw a peak of routing changes from Facebook. That’s when the trouble began.
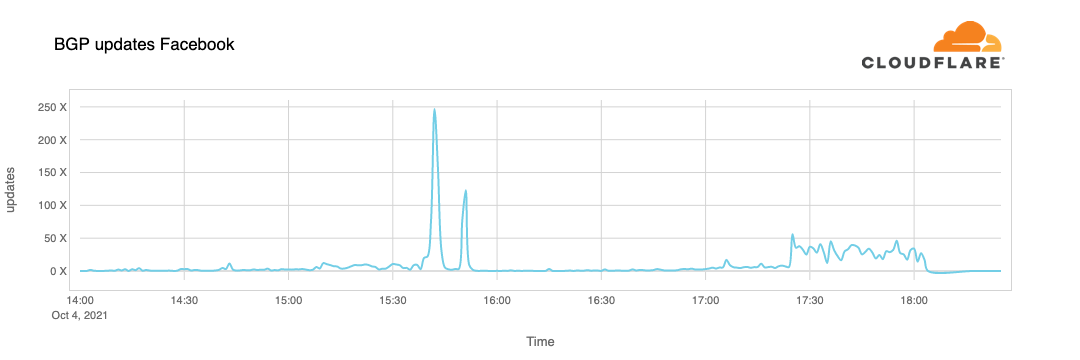
If we split this view by routes announcements and withdrawals, we get an even better idea of what happened. Routes were withdrawn, Facebook’s DNS servers went offline, and one minute after the problem occurred, Cloudflare engineers were in a room wondering why 1.1.1.1 couldn’t resolve facebook.com and worrying that it was somehow a fault with our systems.

With those withdrawals, Facebook and its sites had effectively disconnected themselves from the Internet.
DNS gets affected
As a direct consequence of this, DNS resolvers all over the world stopped resolving their domain names.
➜ ~ dig @1.1.1.1 facebook.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;facebook.com. IN A
➜ ~ dig @1.1.1.1 whatsapp.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;whatsapp.com. IN A
➜ ~ dig @8.8.8.8 facebook.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;facebook.com. IN A
➜ ~ dig @8.8.8.8 whatsapp.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;whatsapp.com. IN A
This happens because DNS, like many other systems on the Internet, also has its routing mechanism. When someone types the https://facebook.com URL in the browser, the DNS resolver, responsible for translating domain names into actual IP addresses to connect to, first checks if it has something in its cache and uses it. If not, it tries to grab the answer from the domain nameservers, typically hosted by the entity that owns it.
If the nameservers are unreachable or fail to respond because of some other reason, then a SERVFAIL is returned, and the browser issues an error to the user.
Again, our learning center provides a good explanation on how DNS works.
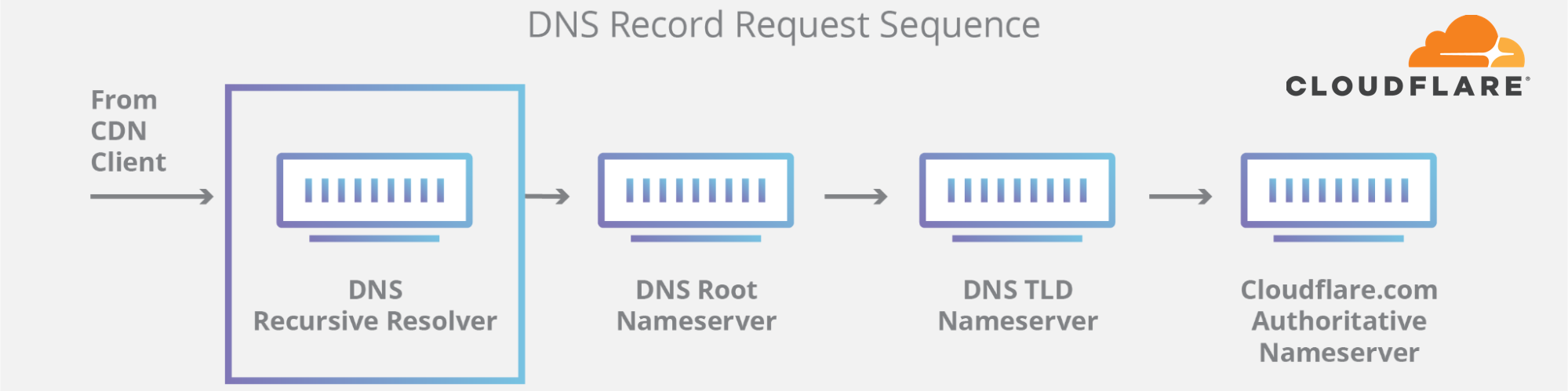
Due to Facebook stopping announcing their DNS prefix routes through BGP, our and everyone else's DNS resolvers had no way to connect to their nameservers. Consequently, 1.1.1.1, 8.8.8.8, and other major public DNS resolvers started issuing (and caching) SERVFAIL responses.
But that's not all. Now human behavior and application logic kicks in and causes another exponential effect. A tsunami of additional DNS traffic follows.
This happened in part because apps won't accept an error for an answer and start retrying, sometimes aggressively, and in part because end-users also won't take an error for an answer and start reloading the pages, or killing and relaunching their apps, sometimes also aggressively.
This is the traffic increase (in number of requests) that we saw on 1.1.1.1:
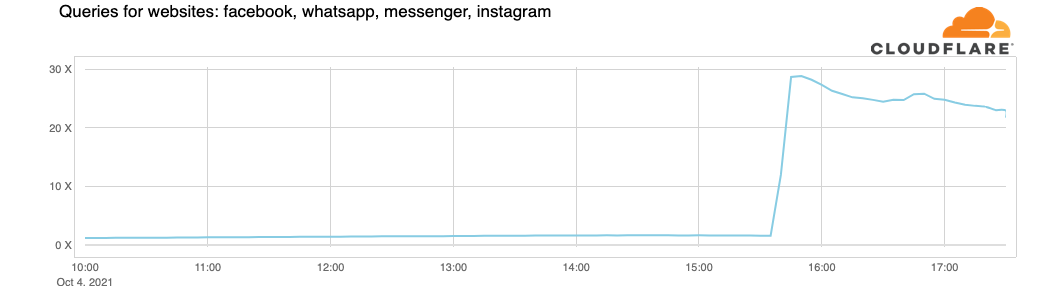
So now, because Facebook and their sites are so big, we have DNS resolvers worldwide handling 30x more queries than usual and potentially causing latency and timeout issues to other platforms.
Fortunately, 1.1.1.1 was built to be Free, Private, Fast (as the independent DNS monitor DNSPerf can attest), and scalable, and we were able to keep servicing our users with minimal impact.
The vast majority of our DNS requests kept resolving in under 10ms. At the same time, a minimal fraction of p95 and p99 percentiles saw increased response times, probably due to expired TTLs having to resort to the Facebook nameservers and timeout. The 10 seconds DNS timeout limit is well known amongst engineers.
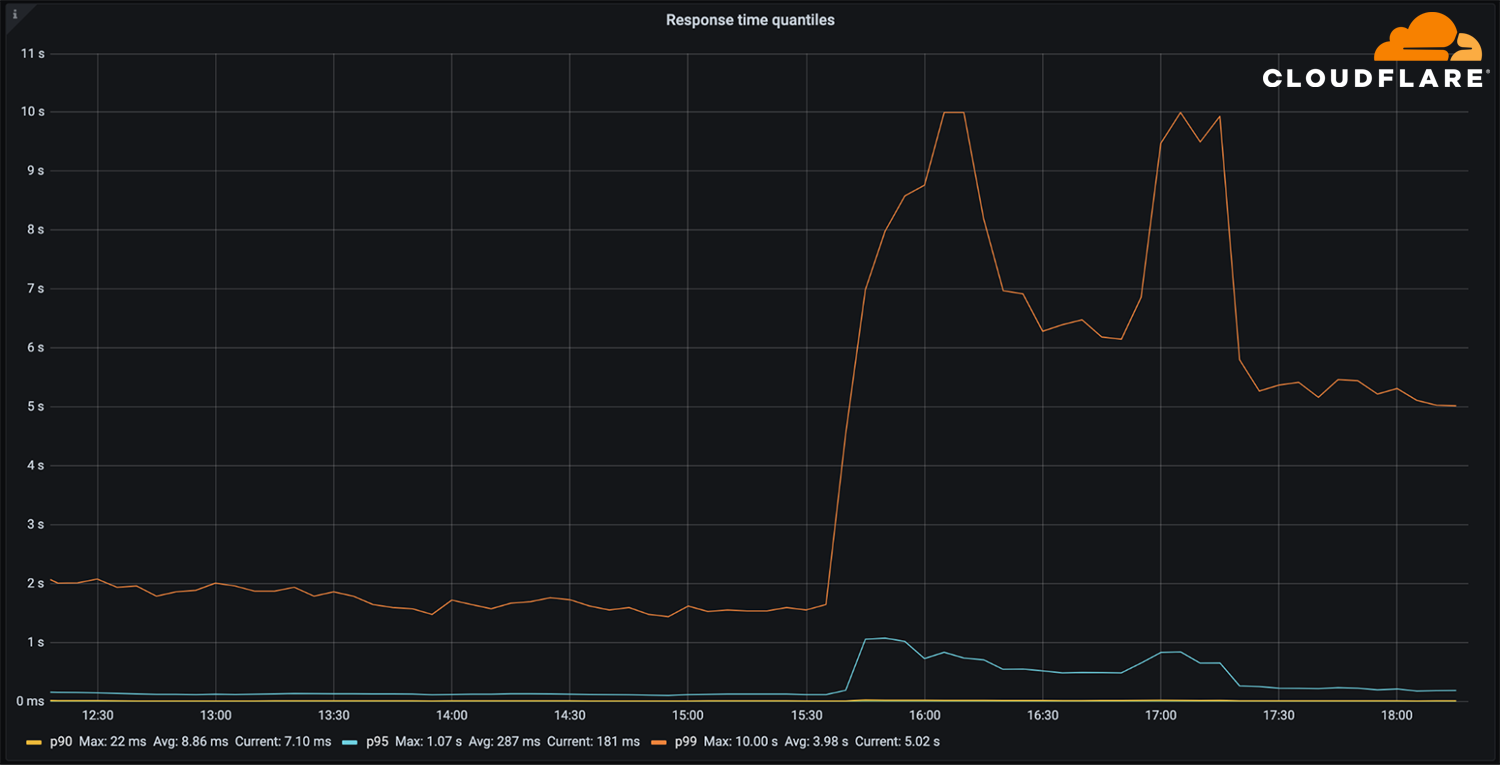
Impacting other services
People look for alternatives and want to know more or discuss what’s going on. When Facebook became unreachable, we started seeing increased DNS queries to Twitter, Signal and other messaging and social media platforms.
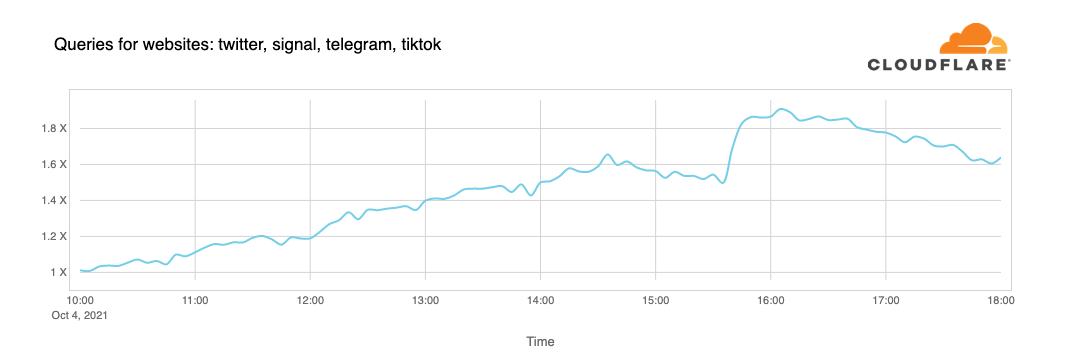
We can also see another side effect of this unreachability in our WARP traffic to and from Facebook's affected ASN 32934. This chart shows how traffic changed from 15:45 UTC to 16:45 UTC compared with three hours before in each country. All over the world WARP traffic to and from Facebook’s network simply disappeared.
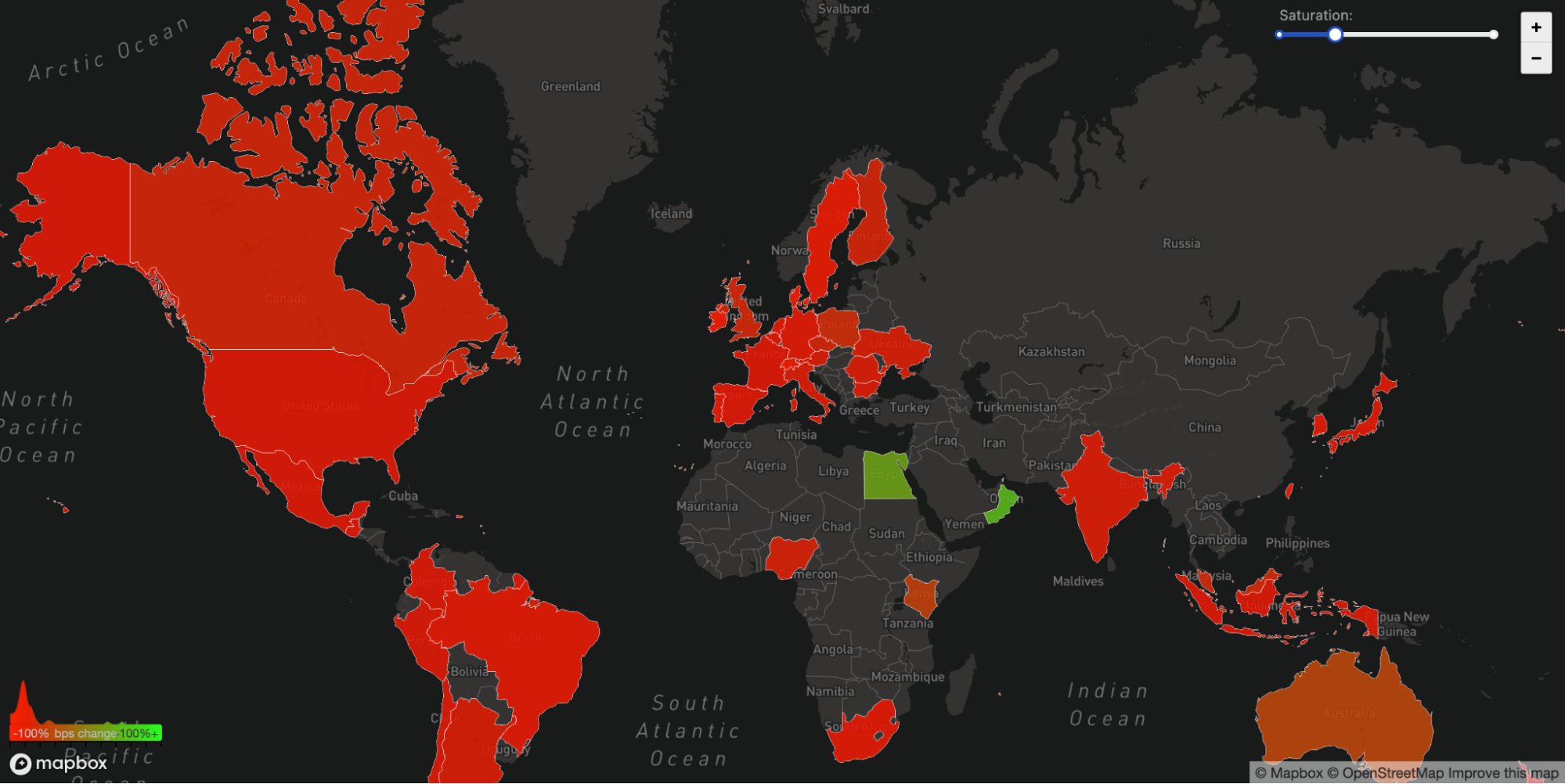
The Internet
Today's events are a gentle reminder that the Internet is a very complex and interdependent system of millions of systems and protocols working together. That trust, standardization, and cooperation between entities are at the center of making it work for almost five billion active users worldwide.
Update
At around 21:00 UTC we saw renewed BGP activity from Facebook's network which peaked at 21:17 UTC.

This chart shows the availability of the DNS name 'facebook.com' on Cloudflare's DNS resolver 1.1.1.1. It stopped being available at around 15:50 UTC and returned at 21:20 UTC.
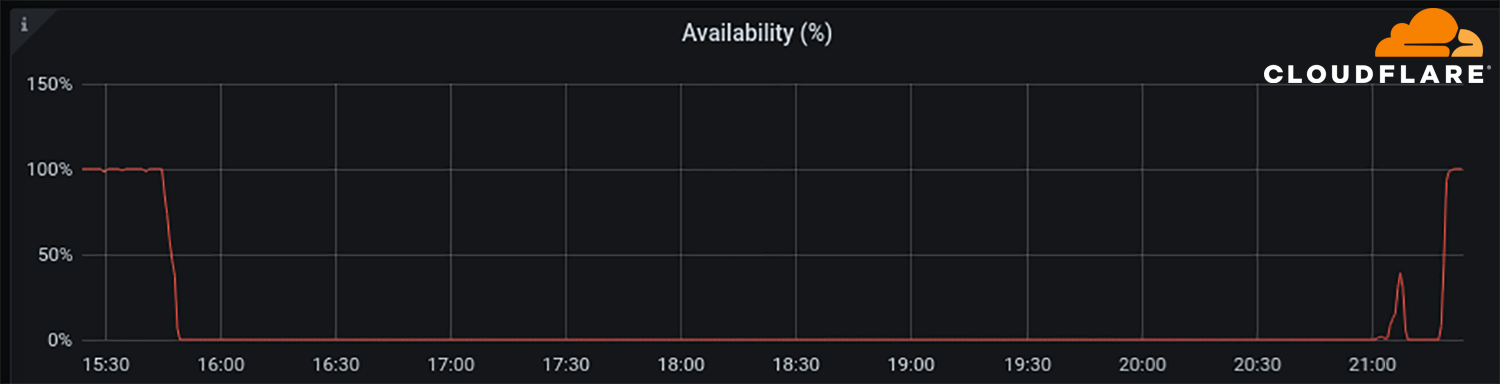
Undoubtedly Facebook, WhatsApp and Instagram services will take further time to come online but as of 21:28 UTC Facebook appears to be reconnected to the global Internet and DNS working again.
Here's an official statement from Facebook. The reason for the access problems was a change in the configuration of the backbone routers. So they did cause it themselves, and in the process allowed the biggest user data leak. Now we can speculate about the real reasons and the intent, because not for a second should we believe their "innocent mistake" explanation. ")

 engineering.fb.com
engineering.fb.com
Update about the October 4th outage
To all the people and businesses around the world who depend on us, we are sorry for the inconvenience caused by today’s outage across our platforms. We’ve been working as hard as we can to restore…
To all the people and businesses around the world who depend on us, we are sorry for the inconvenience caused by today’s outage across our platforms. We’ve been working as hard as we can to restore access, and our systems are now back up and running. The underlying cause of this outage also impacted many of the internal tools and systems we use in our day-to-day operations, complicating our attempts to quickly diagnose and resolve the problem.
Our engineering teams have learned that configuration changes on the backbone routers that coordinate network traffic between our data centers caused issues that interrupted this communication. This disruption to network traffic had a cascading effect on the way our data centers communicate, bringing our services to a halt.
Our services are now back online and we’re actively working to fully return them to regular operations. We want to make clear at this time we believe the root cause of this outage was a faulty configuration change. We also have no evidence that user data was compromised as a result of this downtime.
People and businesses around the world rely on us everyday to stay connected. We understand the impact outages like these have on people’s lives, and our responsibility to keep people informed about disruptions to our services. We apologize to all those affected, and we’re working to understand more about what happened today so we can continue to make our infrastructure more resilient.
Here is what rt.com says
First they published article 5 Oct, 2021 01:35
Then the second article on 5 Oct, 2021 04:22
Well one thing is clear; it wasn´t only FB and co. - those were only ones that everybody noticed and got biggest attention.
This looks like something on much larger scale, and at this point in time we can only speculate...
The info that employers couldn´t get in the building also smells fishy; why would the building itself cut out the employers? The security at the doors is internal HR system - maybe it was also affected if they had internet issues but I doubt that; maybe someone had a reason to lock out personnel from the building for a couple of hours....
First they published article 5 Oct, 2021 01:35
‘Who broke the Internet?!’ Major outages hit Bank of America, Southwest Airlines, Zoom, Snapchat & others after FB crash
Many of the world’s largest apps and websites, including for banks and airlines, faced a cascade of outages all in the space of a few hours, prompting panic among netizens as some demanded to know who “broke” the internet.
While the glitches affected a number of popular social media platforms – among them Twitter, Reddit, Facebook, Instagram and SnapChat – other more significant institutions also faced major tech issues on Monday, such as Bank of America, Southwest Airlines, the professional networking site LinkedIn and the cryptocurrency exchange Coinbase, all according to outage tracker DownDetector.
The tracking website noted that the problems at Facebook marked the “largest outage we’ve ever seen on DownDetector” with more than “10.6 million problem reports from all over the globe,” however the platform, along with the Facebook-owned site Instagram, appear to have come back to life since, having been down for some six hours.
Chat apps such as Zoom and Telegram, as well as Gmail – among the world’s most heavily trafficked email services – were also reportedly caught up in the internet-wide meltdown. All three have seen a major surge in use amid the Covid-19 pandemic, which has driven many firms to transition to more remote-work. Monday’s glitches were sure to cause headaches for countless professionals attempting to work from home, even prompting some to demand to know “who broke the internet.”
Other users offered some novel theories as to what might have caused the outages, ranging from a widespread cyber attack, a clandestine CIA operation, to the usual scapegoat – the “Russians.”
It remains unclear exactly what caused the widespread outages on Monday, though a Facebook employee who declined to be named told NBC the company faced a DNS [Domain Name System] problem, referring to a ‘phone book’-like system used to look up individual websites. The employee added that there is “no reason at this point to suspect anything malicious,” but the outage nonetheless affected “pretty much everything” at Facebook before the issue was resolved later on Monday evening. The six-hour outage reportedly cost the platform a cool $6 billion.
Then the second article on 5 Oct, 2021 04:22
Facebook blames ‘faulty configuration change’ for massive outage amid calls to ‘break up’ tech giant
Facebook has issued a mea culpa after disrupting the business and social interactions of millions of users as a Facebook-owned social media trio lagged for over six hours, while blaming an engineering error for the web apocalypse.
Facebook has confirmed that a routing problem throttled its services, bringing operations at its site, as well as that of Facebook-owned Instagram and WhatsApp, to a screeching halt.
“Our engineering teams have learned that configuration changes on the backbone routers that coordinate network traffic between our data centers caused issues that interrupted this communication,” the company said in a blog post on Monday.
While Facebook did not shed much light on the issue, a Reddit user who claimed to work for the company said the configuration change prevented Facebook IT experts – people “with knowledge what to actually do” to remedy the bug – from remotely accessing the tools needed for the fix. The alleged Facebook staffer added that while an “emergency” plan to gain physical access to the routers was activated, the whole operation posed a logistical challenge – all made worse by “lower staffing in data centers due to pandemic measures.”
The disruption, Facebook admitted, “had a cascading effect on the way our data centers communicate, bringing our services to a halt.”
The social media giant was quick to assure that there was no indication that user data was compromised while its services were off the grid, noting that it was “actively working to fully return them to regular operations.”
Echoing CEO Mark Zuckerberg's penitent message to users forced to quit their preferred social media platform cold turkey – albeit for a mere six hours – Facebook apologized to “all those affected,” promising to find the root cause of the problem and make its infrastructure more error-proof.
Facebook was not the only one affected by the major internet calamity on Monday. Outages were reported across a variety of sites, including Twitter, Reddit, Bank of America, Southwest Airlines, LinkedIn, Snapchat and other major companies. What resembled a domino effect prompted some netizens to suggest that a sinister cyber attack, or even a clandestine intelligence operation, could have been behind the meltdown.
Others have seized on the occasion to insist that Facebook amassed too much control over people’s lives and should be broken up. In a swipe at Facebook, Democratic US Rep. Alexandria Ocasio-Cortez blasted it as a monopoly whose mission “to either own, copy, or destroy any competing platform,” and which has led to “incredibly destructive effects on free society and democracy.” “Break them up,” she concluded.
Another staunch proponent of antitrust laws, Sen. Elizabeth Warren of Massachusetts, tweeted rather succinctly: “We should break up Big Tech.”
Well one thing is clear; it wasn´t only FB and co. - those were only ones that everybody noticed and got biggest attention.
This looks like something on much larger scale, and at this point in time we can only speculate...
The info that employers couldn´t get in the building also smells fishy; why would the building itself cut out the employers? The security at the doors is internal HR system - maybe it was also affected if they had internet issues but I doubt that; maybe someone had a reason to lock out personnel from the building for a couple of hours....
Would love to see this happen globally with the systems that are attempting to enforce ‘covid passports’. 
can I plz has # t a k e d o w n ??
Imagine all those staff at ‘bookface’ not being able to get into work. Hilarious! Today I’m enjoying the show!
not being able to get into work. Hilarious! Today I’m enjoying the show!
can I plz has # t a k e d o w n ??
Imagine all those staff at ‘bookface’
not being able to get into work. Hilarious! Today I’m enjoying the show!An outage such as this one from BGP misconfiguration is a valid explanation if they are telling the truth. Also, being locked out of the systems and building etc makes sense as most of these security systems rely on the core network which relies on BGP enabled routing especially for a big organisation who has their own ASN. Think ASN as a large collection of IP addresses dedicated to an organisation.
Networks become more intertwined and complex as they grow and there is sometimes not enough technical expertise in the ranks or board sponsorship to keep technical debt in check and build redundancies at all levels. Such initiatives are cash burners and hurt share prices. Therefore, one major issue in a section of the network will impact something else totally unrelated and the troubleshooting can take hours to days because not one person understands the architecture completely.
Other explanation would be BGP poisoning ie someone gaining access to a core router and advertising incorrect routes for Facebook ASN which would divert data to non-Facebook servers setup to exfiltrate user data including user-credentials. Something like this can only be done by a large player, maybe our friends in the middle-east.
Adding further, if the PTB wants to blackmail a big organisation like Facebook, they only need to arm-twist the larger service providers to drop all internet packets to Facebook’s ASN. Its no surprise that the big families has controlling shares in all larger internet service providers. The types who run the backbones within national boundaries and internationally.
Networks become more intertwined and complex as they grow and there is sometimes not enough technical expertise in the ranks or board sponsorship to keep technical debt in check and build redundancies at all levels. Such initiatives are cash burners and hurt share prices. Therefore, one major issue in a section of the network will impact something else totally unrelated and the troubleshooting can take hours to days because not one person understands the architecture completely.
Other explanation would be BGP poisoning ie someone gaining access to a core router and advertising incorrect routes for Facebook ASN which would divert data to non-Facebook servers setup to exfiltrate user data including user-credentials. Something like this can only be done by a large player, maybe our friends in the middle-east.
Adding further, if the PTB wants to blackmail a big organisation like Facebook, they only need to arm-twist the larger service providers to drop all internet packets to Facebook’s ASN. Its no surprise that the big families has controlling shares in all larger internet service providers. The types who run the backbones within national boundaries and internationally.

Ocean
The Living Force
From an IC insider :-
The Facebook situation is entirely manufactured. The US Gov is attempting to commandeer their ability to censor you, not stop it.
The "urgency" around the Facebook situation tells you that the US Gov and IC understand they have a substantial risk of failure elsewhere.
-
It is an indication that they are seeking alternate roads in order to accomplish their goal of stealing your rights and liberties.
Reporters and people already recognize this and are raising red flags all over the place.
The Facebook situation is entirely manufactured. The US Gov is attempting to commandeer their ability to censor you, not stop it.
The "urgency" around the Facebook situation tells you that the US Gov and IC understand they have a substantial risk of failure elsewhere.
-
It is an indication that they are seeking alternate roads in order to accomplish their goal of stealing your rights and liberties.
Reporters and people already recognize this and are raising red flags all over the place.
FWIW, an article by Kit Knightly at Off-Guardian on this subject. ")

 off-guardian.org
off-guardian.org
The real story behind Facebook’s terrible, horrible, no good, very bad week
Facebook suffered a massive outage on Monday. At the same time a high profile “whistleblower” has come forward to dish the FB dirt. These two things have combined to create a perfect st…
off-guardian.org
Trending content
-

-

-
Thread 'Coronavirus Pandemic: Apocalypse Now! Or exaggerated scare story?'
- wanderingthomas
Replies: 30K -